This is a project on Siri-like voice recognition using Raspberry Pi, it's useful for home automation control system. I use three components for the project, code is mainly scrapped out from various Internet sources
- A speech-to-text component that will do the voice recognition
- Some “brains” to analyze the so captured text
- A text to speech component that will speak out the result from component 2
The hardware required is a Raspberry Pi with Internet connectivity and a USB microphone. Pi is running the 2012-12-16-wheezy-raspbian image; I don’t have a USB microphone, but I have a USB webcam (Logitech V-UAV35) with in-built microphone, so that worked out fine without any driver installation.
This is a post explaining this project in detail: Raspberry Pi Voice Recognition Works Like Siri
This is a post explaining this project in detail: Raspberry Pi Voice Recognition Works Like Siri
Speech recognition for Raspberry Pi can be done in number of ways, but I thought the most elegant would be to use Google’s voice recognition functions. I used this bash script to get that part done (source):
#!/bin/bash arecord -D "plughw:1,0" -q -f cd -t wav | ffmpeg -loglevel panic -y -i - -ar 16000 -acodec flac file.flac > /dev/null 2>&1 wget -q -U "Mozilla/5.0" --post-file file.flac --header "Content-Type: audio/x-flac; rate=16000" -O - "http://www.google.com/speech-api/v1/recognize?lang=en-us&client=chromium" | cut -d\" -f12 >stt.txt cat stt.txt rm file.flac > /dev/null 2>&1
..and then set it to executable:
chmod +x stt.sh
You may need to install ffmpeg
sudo apt-get install ffmpeg
So what this does is to record to a flac file from the USB microphone until you press Ctrl+C and then passes that file to Google for analysis, which in turn returns the recognized text. Lets give it a try:
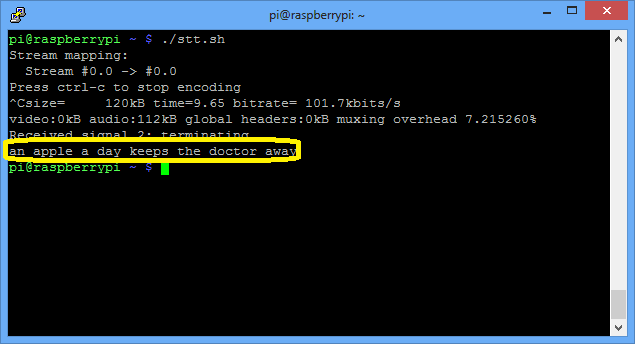
It work pretty good even with my bad accent. The output is saved to stt.txt file.
Now onto the “brains” section, this is with no doubt a task for Wolfram Aplha. I used Python to interface with it, there is already a library to use. It is pretty easy to install, just follow the instructions in the link. I had to get an API key, which is a 2 minute task and gives you 2000 queries a month.
#!/usr/bin/python
import wolframalpha
import sys
#Get a free API key here http://products.wolframalpha.com/api/
#I may disable this key if I see lots of abuse
app_id='Q59EW4-7K8AHE858R'
client = wolframalpha.Client(app_id)
query = ' '.join(sys.argv[1:])
res = client.query(query)
if len(res.pods) > 0:
texts = ""
pod = res.pods[1]
if pod.text:
texts = pod.text
else:
texts = "I have no answer for that"
print texts
else:
print "I am not sure"
.. and lets try it out with the questions that keep me up at night:
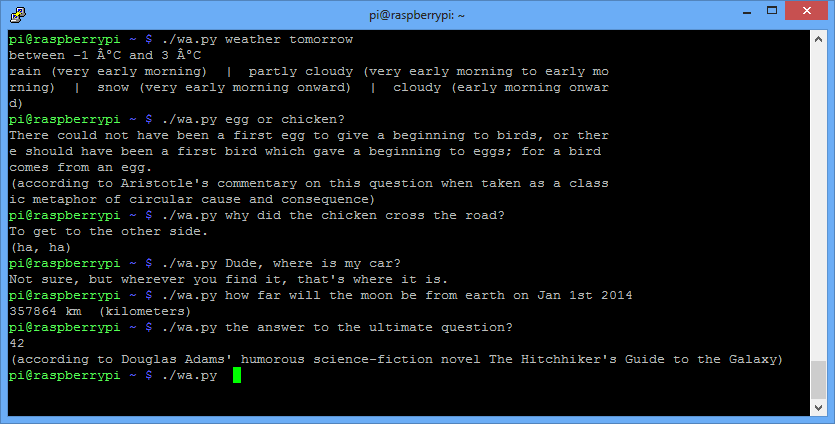
yep, brains are there. Now to the last part: speaking that answer out. Sure enough, we use Google’s speech services again (source)
#!/bin/bash
say() { local IFS=+;/usr/bin/mplayer -ao alsa -really-quiet -noconsolecontrols "http://translate.google.com/translate_tts?tl=en&q=$*"; }
say $*
..you may need to “sudo apt-get install mplayer” first..
It sounds pretty cool indeed.
So finally a small script to put these to work together:
#!/bin/bash echo Please speak now and press Ctrl+C when done ./stt.sh ./tts.sh $(./wa.py $(cat stt.txt))
So overall a fun project, maybe with some potential to use in home automation.. (4627)
No comments:
Post a Comment
Note: only a member of this blog may post a comment.